

“比特派安卓版让我在加密货币世界中游刃有余。交易速度超快,手续费超低。无论是管理多种加密资产还是参与智能合约项目,都是绝佳选择。”
比特派安卓版
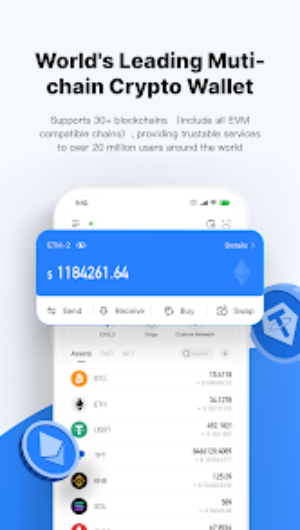
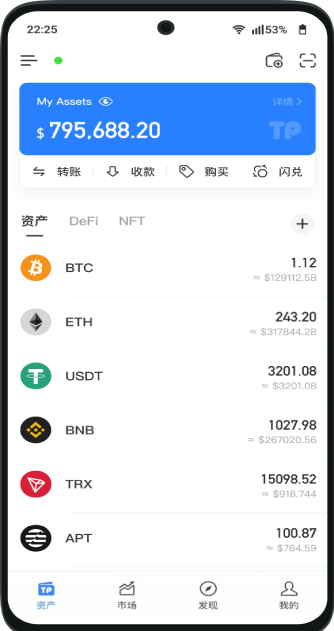
比特派安卓版是一款支持多链的自托管钱包,使用简单安全,深受全球数千万人的信赖与喜爱
我们的应用费率
为您制定定价计划
反馈
人们在谈论什么.

“作为一个新手投资者,比特派安卓版帮助我顺利入门。界面简单易懂,教程详细易学。我现在可以自信地交易和管理我的投资组合”
— IOS用户
“对于我来说,比特派安卓版的安全性是最重要的。它的多重验证和私钥控制让我放心。我在这里处理大量交易,从未感到担忧。”
— 安卓用户
发现
常见问题
区块链是一个共享数据库,存储于其中的数据或信息,具有不可伪造、全程留痕、可以追溯、公开透明和集体维护等特征。可以把区块链理解为一个共享的、不可更改的电子账本,能够在网络中记录交易和跟踪资产。这里的资产可以是有形的(例如房和车),也可以是无形的(例如知识产权、专利和品牌)。几乎任何有价值的东西都可以在区块链网络上进行跟踪和交易,从而降低各方面的风险和成本。 目前区块链技术最大的应用是数字货币,因为支付的本质是“将账户A中减少的金额增加到账户B中”。如果人们有一本公共账簿,记录了所有的账户至今为止的所有交易,那么对于任何一个账户,人们都可以计算出它当前拥有的金额数量。而区块链恰恰是用于实现这个目的的公共账簿,其保存了全部交易记录。 区块链起源于比特币,2008年11月1日,一位自称中本聪(Satoshi Nakamoto)的人发表了《比特币:一种点对点的电子现金系统》一文,阐述了基于P2P网络技术、加密技术、时间戳技术、区块链技术等的电子现金系统的构架理念,这标志着比特币的诞生。两个月后理论步入实践,2009年1月3日第一个序号为0的创世区块诞生。几天后2009年1月9日出现序号为1的区块,并与序号为0的创世区块相连接形成了链,标志着区块链的诞生。
【安卓版本】 安卓手机用户请到比特派安卓版官网下载最新版本。 (注意:比特派安卓版官方网址为:https://www.jike1995.com) 【苹果版本】 点击下方链接查看苹果手机如何在App Store下载比特派安卓版 App?https://www.jike1995.com
相对于私钥掌握在第三方服务商手中的中心化钱包(交易所),去中心化钱包的私钥则由用户自己保存,资产存储在区块链上,用户是真正的数字货币的持有者,钱包只是帮助用户管理链上资产和读取区块链数据的一个工具,所以也就无法控制、窃取、转移你的资产。 因此去中心化的钱包很难被黑客集中攻击,用户也不必担心钱包服务商的自我窃取或者跑路,因为只要创建钱包的时候自己把私钥保管好,您的资产依然在链上,换个钱包一样可以显示出来的。 注意:去中心化钱包一旦丢失、被盗,在没有备份私钥或助记词的情况下是无法找回的,因此一定要安全、正确的备份您的私钥。
矿工费(Gas Fee)也称为网络费,顾名思义就是支付给矿工的手续费,当您在区块链上进行转账时,矿工(或节点)需要把您的转账交易打包并放上区块链,才能使交易完成,在这过程中会消耗区块链的运算资源,因此产生矿工费用。 在EVM兼容链中,手续费是由Gas Price(单价)和消耗的 Gas Limit(数量)来确定的,其中计算公式如下: 矿工费 = Gas Limit * Gas Price Gas Limit数量主要受根据智能合约的内容操作复杂程度影响。操作越多,Gas limit越高。Gas Price是由发起方设置的,发起方设置的Gas Price的价格越高,其发起的交易就能越快被打包。 注: 以太坊(Ethereum)的网络费为ETH; 币安智能链(BNBChain)的网络费为BNB; 波场(TRON)的网络费为TRX; 马蹄(Polygon/Matic)的网络费为MATIC; Solana的网络费为SOL; OKExChain的网络费为OKT; 网络用不完是可以退回的。 转账网络收取的矿工费(网络费)会根据网络的情况而有所不同,一旦确定交易,不管交易是否成功,矿工费都无法退回。 矿工费是由您所选取的转账网络进行收取,比特派安卓版钱包不收取任何费用!
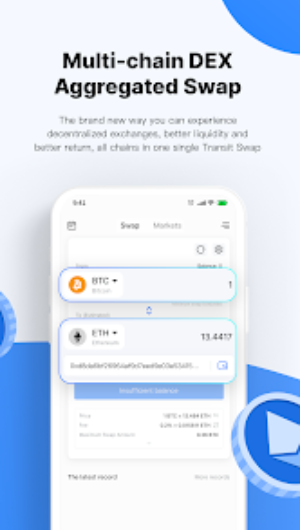
DeFi全称为Decentralized Finance,即“去中心化金融”或者“分布式金融”。它与传统中心化金融相对,指建立在开放的去中心化网络中的各类金融领域的应用,用户无需再在中心化机构的辅助下参与金融市场,而是可以利用去中心化网络中的开源软件获得、交易并借贷资产。通俗的说,就是建立一个对所有人开放的新金融系统,不需要如银行这类的中介机构。 DeFi的目标是建立一个多层面的金融系统,以区块链技术和密码货币为基础,重新创造并完善已有的金融体系。 当前,几乎全部的DeFi项目都在以太坊的区块链上进行,智能合约是 DeFi的主要构建模块。如今最常见的几类 DeFi Dapp主要有Compound、MakerDAO、Synthetix、去中心化交易所(例如Uniswap)等。
界面
看看应用程序里面有什么

比特派安卓版官网Android 和 iOS 下载
3 00 万用户并且还在增加!
专注与比特派安卓版相关报道,区块链行业动态,加密货币百科技术
最近的新闻
数字货币与钱包:一场技术革命的关键组件
2024-04-27 01:43:33
什么是数字货币? 数字货币是一种基于加密技术的数字化货币。与传统货币不同的是,数字货币不受政府或金融机构控制,而是由区块链技术支持进行交易。目前,比特币和以太坊是最为知名的数字货币。 什么是钱包? 钱包是存储、管理数字货币的软件工具。它的主要功能是生成和管理用户的私钥和公钥,进行交易的签名和广播,并提供数字货币地址查询和余额查询等服务。钱包分为热钱包...
TP钱包兑换为什么会有滑点?如何减少滑点?
2024-04-27 00:42:54
什么是TP钱包兑换滑点? TP钱包是一款数字资产管理平台,支持各类主流数字货币的管理和交易,其兑换功能不仅方便快速,同时也提供了时时兑换汇率查询,但在实际操作过程中,会发现兑换时存在一个滑点(Slippage)的问题,即兑换价格和查询到的价格不一致。 滑点产生的原因是什么? 滑点主要是由市场供需及交易对市场深度等因素影响的。因为TP钱包兑换是以交易对...
虚拟币钱包操作指南:如何利用钱包购买数字货
2024-04-26 23:42:13
何为虚拟币钱包? 虚拟币钱包是存储数字货币的地方,它类似于传统钱包,只是它是数字化的,可以存储和管理各种类型的虚拟币,如比特币、以太币等。虚拟币钱包一般需要安装在电脑或移动设备上,同时需要设置私钥才能使用。 能否用虚拟币钱包购买数字货币? 是的,虚拟币钱包可以用来购买数字货币。用户只需要在钱包中选择购买数字货币选项,然后选择所需的货币类型和购买数量...